In an attempt to follow in the footsteps of the progression of natural language processing, I began here with a character level Markov chain. In 1913 Andrey Markov addressed the Imperial Academy of Sciences in St Petersburg with an analysis of Pushkin's Eugene Onegin, I thought I'd follow this thread and instead generate a markov model of a favourite book of mine, "The Picture of Dorian Gray" by Oscar Wilde.
A Markov chain is a stochastic model describing a sequence of possible events in which the probability of each event depends only on the state attained in the previous event. The chain is then used to generate new text based on the transition probabilities that were learned from the training text.
Mathematical Definition
Given a sequence of random variables $X_1,\:X_2,\:X_3,\:\ldots$ which exist in the state space $X_i$ the process is a Markov chain if the probability of moving to the next state depends only on the present state and not on the previous states.
This means that we have:
$$P(X_{n+1} = x \mid X_1 = x_1, \ldots, X_n = x_n) = P(X_{n+1} = x \mid X_n = x_n)$$
Implementation
The implementation of the Markov chain is done in the main.py file. The code is structured as follows:
- The text is read from the file and preprocessed.
- The Markov chain is trained on the text.
- The chain is used to generate new text.
- The chain is visualised with a graph of transition probabilities.
Training
The training of the Markov chain is done by iterating over the text and counting the number of times each character follows a specific sequence of characters. The length of the preceding sequence is defined by the order parameter.
Generation
The generation of new text is done by starting with a random sequence of characters and then using the Markov chain to predict the next character. The next character is chosen based on the transition probabilities learned during training. The training doesn't calculate probabilities, instead it stores a count for each transition. Therefore the probabilities are calculated by normalising the counts.
This character is then added to the sequence and the process is repeated until the desired length of the text is reached.
Temperature
To control the randomness of the generated text, a temperature parameter can be used. The temperature controls the randomness of the next character by scaling the probabilities.
The temperature scales the counts of the transitions by raising them to the power of 1 / temperature. This means that a higher temperature will result in a more uniform distribution of the probabilities, while a lower temperature will result in a more deterministic distribution.
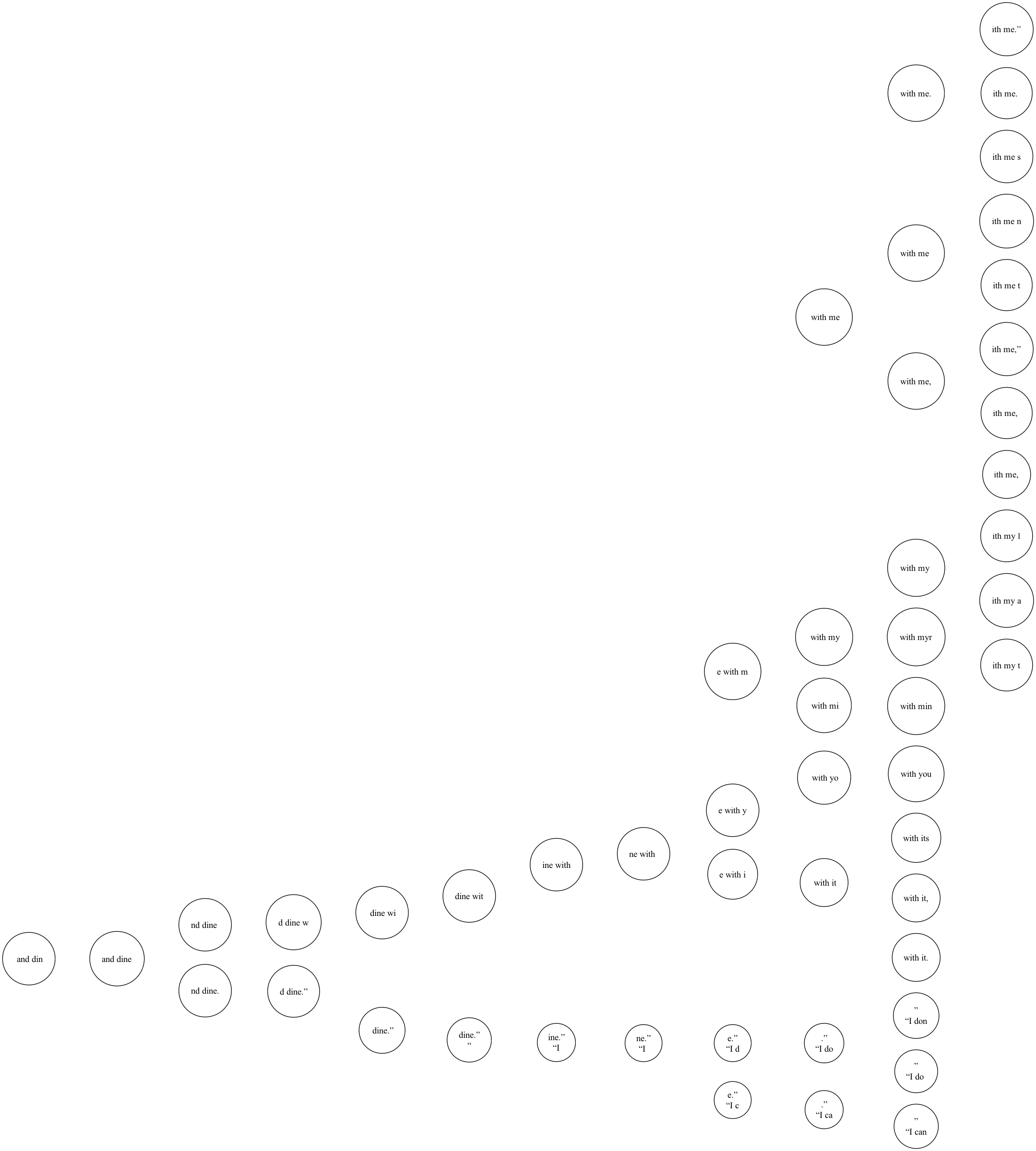
Visualisation
The visualisation of the Markov chain is done by creating a graph of the transition probabilities. The graph is created using the graphviz library.
The graph is created by collecting the top 3 most probable transitions for each state and then creating a directed graph with the probabilities as the weights of the edges.
You can check out the code for this project here.